Flink知识汇总
架构
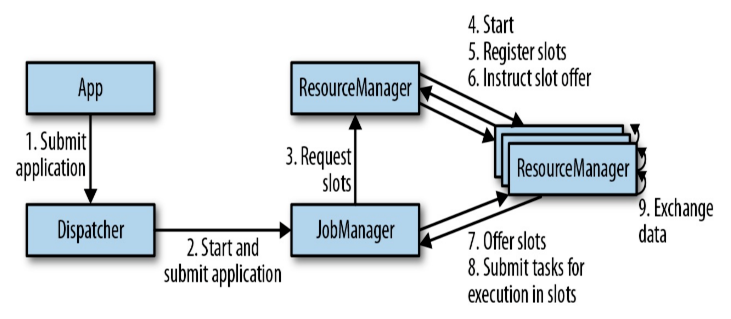
JM、TM、Dispatcher、ResourceManager
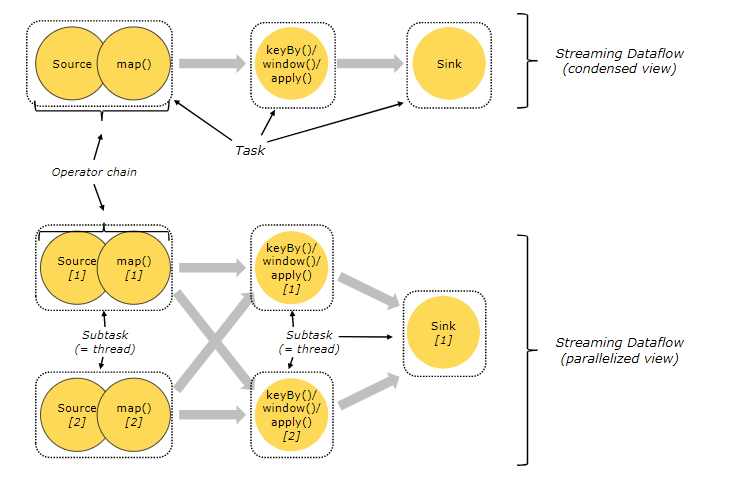
Task与SubTask
两者的区别
计算时为了减少线程间的切换,将不同的算子chian在一起,降低延迟提高整体吞吐量,有一些算子是不能被chian在一起的,比如keyBy、Winodws这些
一个Task可以按照并行度拆分成多个SubTask,每个单独的SubTask都是一个单独的线程
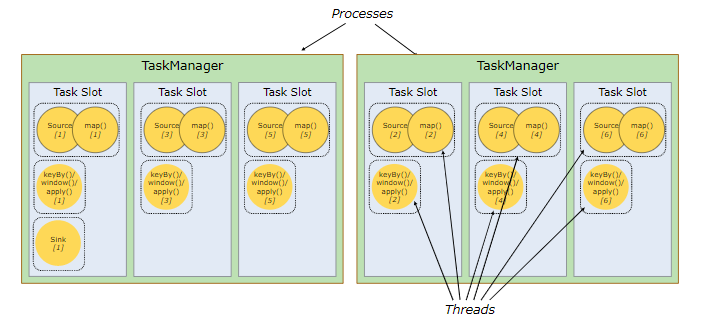
资源管理
- TM 上会分配多个Slot
- SubTask会分配到具体的Slot中执行
- 每个SubTask时独立的线程
共享所属的 TaskManager 进程的TCP 连接,降低整体的性能开销

每个操作需要的资源都是不尽相同的,资源分配不均怎么办?
Flink 允许多个 subtasks 共享 slots,只要它们来自同一个 Job 就可以
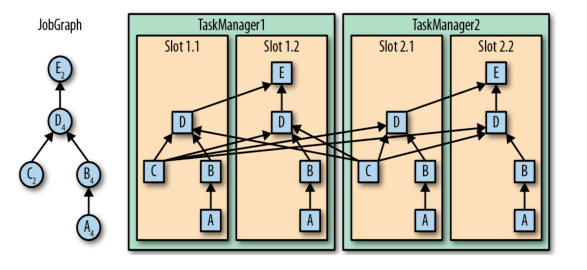
一个Job到底需要多少个Slot?
JobGraph中max
状态
Keyed State 与 Operator State
支持TTL
MemoryStateBackend、FsStateBackend、RocksDBStateBackend
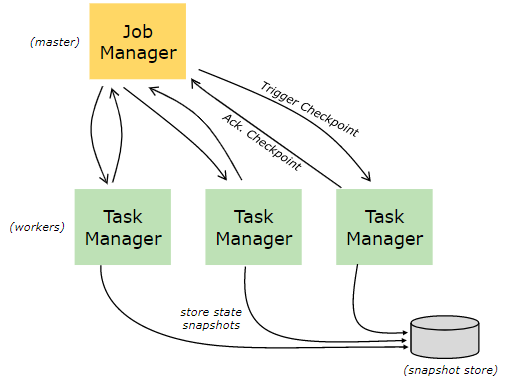
CheckPoint
机制,周期性的插入barrier,算子收到barrier后生成快照
- 暂停新数据处理,将接收到的数据缓存
- 持久化当前状态
- 处理新数据 + 缓存后数据
savepoint知识cp的一种特殊形式,允许手动执行并存入到指定路径下。
时间
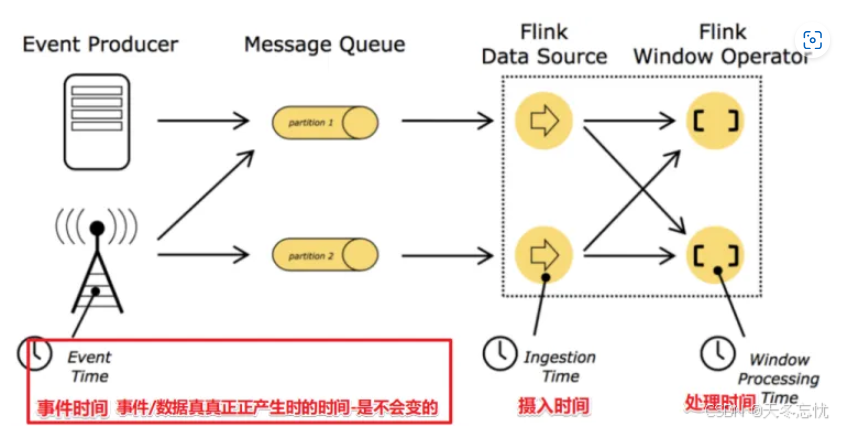
EventTime:作为事件(数据)真正发生、产生之时的时间戳记录,它锚定了事件的源头时间,不受数据后续流转环节的干扰,比如用户在电商平台下单操作瞬间对应的时间,即便后续网络波动致数据传输受阻,该时间依旧锁定下单那一刻。
IngestionTime:侧重标记数据抵达流处理系统的时间节点,当数据跨越系统边界进入 Flink 体系时,此刻的系统时钟时间即为 IngestionTime,反映数据流入的 “入门时刻”。
ProcessingTime:聚焦数据在流处理系统内被具体处理、计算的当下系统时间,同一批数据在不同负载时段处理,ProcessingTime 会因处理时刻差异而不同。
窗口
Tumbling Windows
Sliding Windows
Session Windows:
// 以处理时间为衡量标准,如果10秒内没有任何数据输入,就认为会话已经关闭,此时触发统计
window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
Global Windows:
// 当单词累计出现的次数每达到10次时,则触发计算,计算整个窗口内该单词出现的总数
window(GlobalWindows.create()).trigger(CountTrigger.of(10)).sum(1).print();
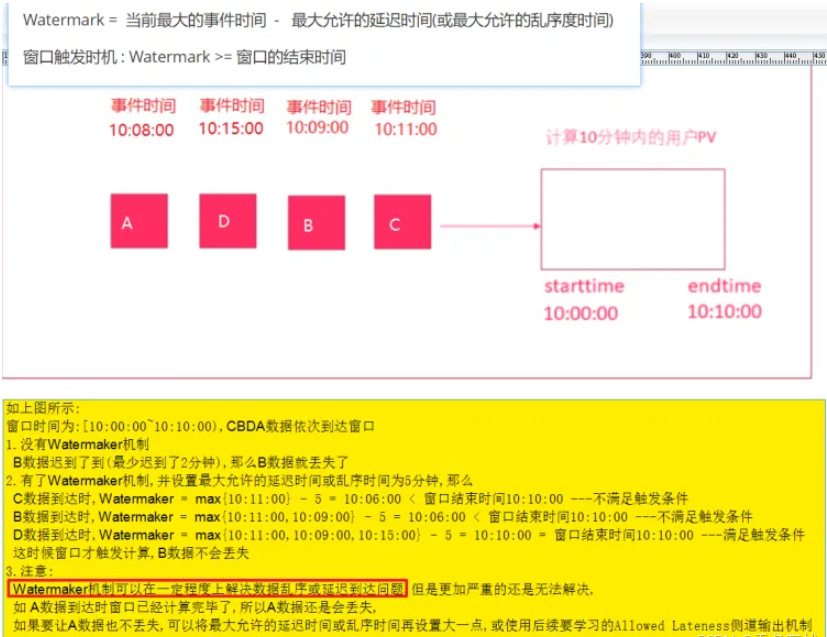
水位线
目的:当使用了EventTime,应对乱序问题。
背压调优
12. Flink 背压 - 从原理到调优的全面指南 - 知乎 (zhihu.com)
- 监控先行:利用Web UI和Metrics快速定位瓶颈算子;(监控)
- 对症下药:区分数据倾斜、资源不足、阻塞操作等场景,针对性优化;(诊断)
- 预防为主:设计作业时预判热点数据,合理设置并行度与状态后端。(预防)
危害
- 数据延迟:下游处理能力不足,数据堆积在内存甚至写入磁盘(如RocksDB),延迟从秒级恶化到分钟级。
- 资源耗尽:TaskManager内存爆满,触发OOM(OutOfMemoryError),任务频繁重启。
- 雪崩效应:背压向上游传递,最终导致Kafka消费者阻塞,影响整个数据管道。
根本原因
下游算子处理速度跟不上上游数据生产速度时
间接原因
原因1:数据倾斜
原因2:资源不足
原因3:阻塞操作
原因4:反压传播机制
Flink通过动态反馈机制逐级向上游传递背压信号:
- 下游TaskManager的输入缓冲区(Input Buffer)满;
- 通过Netty告知上游TaskManager降低发送速率;
- 最终源头(如Kafka Consumer)暂停读取数据。
优化手段
CPU利用率高且数据分布均匀扩并行度
打散热点Key/ 预聚合
同步代码异步化
增量Checkpoint+异步
增加TaskManager网络缓冲区
Exactly-Once
Flink Exactly-once实现原理解析 - 知乎 (zhihu.com)
Flink Exactly-once 实现原理解析-阿里云开发者社区 (aliyun.com)
最多一次(At-most-Once):这种语义理解起来很简单,用户的数据只会被处理一次,不管成功还是失败,不会重试也不会重发。
至少一次(At-least-Once):这种语义下,系统会保证数据或事件至少被处理一次。如果中间发生错误或者丢失,那么会从源头重新发送一条然后进入处理系统,所以同一个事件或者消息会被处理多次。
精确一次(Exactly-Once):表示每一条数据只会被精确地处理一次,不多也不少。
End-to-End Exactly Once
source 端 —— 数据可重放
内部保证 —— 开启checkpoint且精准一次
sink 端 —— 从故障恢复时,数据不会重复写入外部系统(幂等写入、事务写入)