2.1.3
互联网金融飞速发展,使得个人金融理财变得越来越容易。而其中信用评分技术是一种对贷款申请人(信用卡申请人)做风险评估分值的统计模型,可以根据客户提供的资料、客户的历史数据、第三方平台数据(芝麻分、京东、微信等),对客户的信用进行评估。现要求根据提供的Finance数据集,选择合适的特征,开发一个申请的评分模型,对未来一段时间内借贷人出现违约的概率进行预测,对客户信用进行评估打分。提供的数据集样本数据一共15000条,10个自变量,1个因变量(SeriousDlqin2yrs)。在开发评分模型之前,首先要对数据进行数据清洗,请补全2.1.3.ipynb代码完成下面的数据预处理任务,并设计一套标注流程规范:
(1)正确加载数据集,并显示前五行的数据;
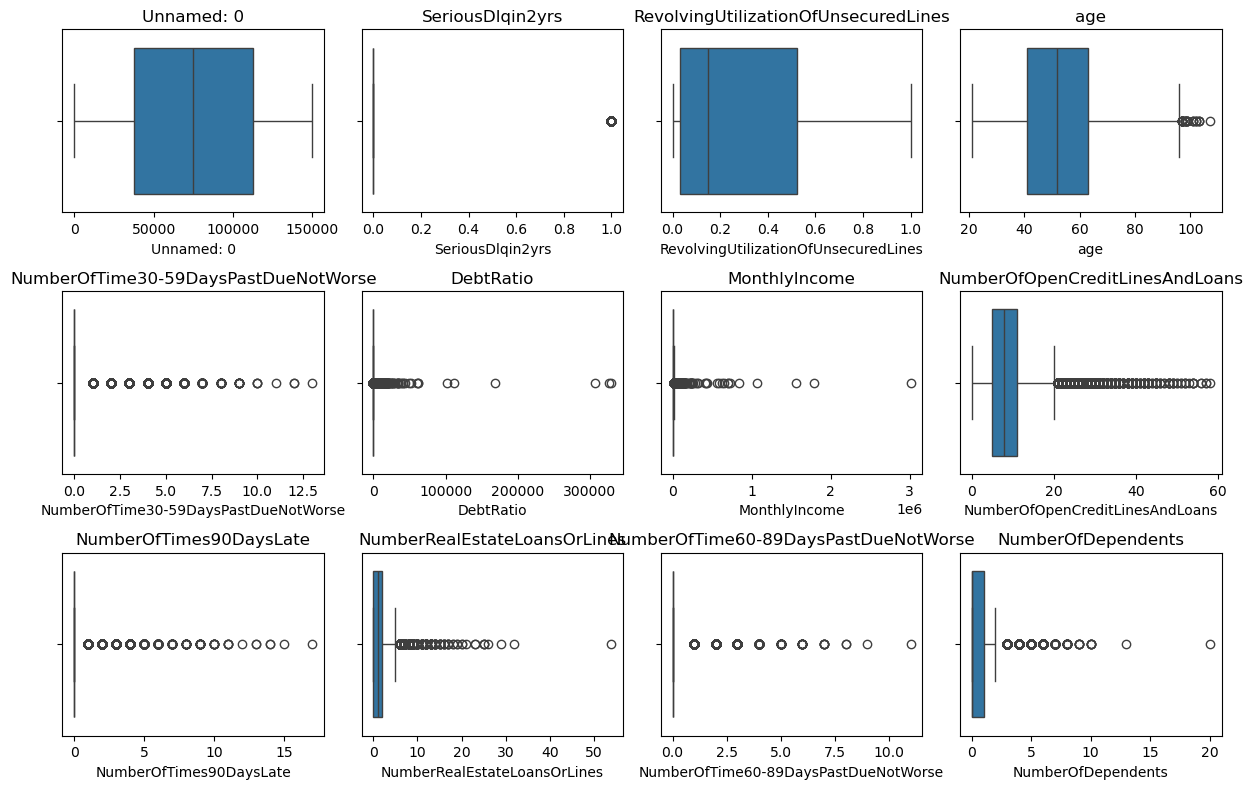
(2)检查数据集中的异常值并处理异常值,使用箱线图检测异常值,使用IQR方法处理异常值;
设置图像的尺寸为12英寸宽和8英寸高;
将画布分成3行4列,总共可以容纳12个子图;
(3)检查数据集中的重复值并删除所有重复值,并记录删除的行数;
(4)对数据进行归一化处理;
(5)创建新的特征IncomeToDebtRatio,MonthlyIncome,并添加到数据集中;
(6)将SeriousDlqin2yrs设为目标变量并标注;
(7)对数据进行划分;
(8)保存处理后的数据,并命名为:2.1.3_cleaned_data.csv,保存到考生文件夹;
(9)制定数据清洗和特征工程规范,将答案写到答题卷文件中,答题卷文件命名为“2.1.3.docx”,保存到考生文件夹;
(10)将以上代码以及运行结果,以html格式保存并命名为2.1.3.html,保存到考生文件夹,考生文件夹命名为“准考证号+身份证后6位”。
import pandas as pd
# 加载数据
data = pd.read_csv('finance数据集.csv')
# 显示前五行的数据
print(data.shape)
import matplotlib.pyplot as plt
import seaborn as sns
# 设置图像尺寸
plt.figure(figsize=(12, 8))
# 识别数值列用于箱线图
numeric_cols = data.select_dtypes(include=['float64', 'int64']).columns
# 创建箱线图
for i, col in enumerate(numeric_cols, 1):
plt.subplot(3, 4, i)
sns.boxplot(x=data[col])
plt.title(col)
plt.tight_layout()
plt.show()
# 使用IQR处理异常值
Q1 = data[numeric_cols].quantile(0.25)
Q3 = data[numeric_cols].quantile(0.75)
IQR = Q3- Q1
# 移除异常值
data_cleaned = data[~((data[numeric_cols] < (Q1 - 1.5 * IQR)) | (data[numeric_cols] > (Q3 + 1.5 * IQR))).any(axis=1)]
# 检查处理重复值
duplicates = data_cleaned.duplicated()
num_duplicates = duplicates.sum()
data_cleaned = data_cleaned[~duplicates]
print(f'删除的重复行数: {num_duplicates}')
#对数据进行归一化处理 (最小最大差异化的方法)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data_cleaned[numeric_cols] = scaler.fit_transform(data_cleaned[numeric_cols])
# 设定目标变量
target_variable = 'SeriousDlqin2yrs'
from sklearn.model_selection import train_test_split
# 定义特征和目标
X = data_cleaned.drop(columns=[target_variable]) #1分
y = data_cleaned[target_variable] #1分
# 划分数据(训练集占80%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 显示划分后的数据形状
print(f'训练数据形状: {X_train.shape}')
print(f'测试数据形状: {X_test.shape}')
# 保存清洗后的数据到CSV
cleaned_file_path = '2.1.3_cleaned_data.csv'
data_cleaned.to_csv(cleaned_file_path, index=False)
(142577, 12)
删除的重复行数: 3
训练数据形状: (61105, 11)
测试数据形状: (15277, 11)
import pandas as pd
# 加载数据
data = pd.read_csv('finance数据集.csv')
# 显示前五行的数据
print(data.head(5))
Unnamed: 0 ... NumberOfDependents
0 1 ... 2
1 2 ... 1
2 3 ... 0
3 4 ... 0
4 5 ... 0
[5 rows x 12 columns]
import matplotlib.pyplot as plt
import seaborn as sns
# 设置图像尺寸
plt.figure(figsize=(12, 8))
# 识别数值列用于箱线图
print(data.select_dtypes(include=['float64', 'int64']))
numeric_cols = data.select_dtypes(include=['float64', 'int64']).columns
print(numeric_cols)
# 创建箱线图
for i, col in enumerate(numeric_cols, 1):
plt.subplot(3, 4, i)
sns.boxplot(x=data[col])
plt.title(col)
plt.tight_layout()
plt.show()
Unnamed: 0 ... NumberOfDependents
0 1 ... 2
1 2 ... 1
2 3 ... 0
3 4 ... 0
4 5 ... 0
... ... ... ...
142572 149996 ... 0
142573 149997 ... 2
142574 149998 ... 0
142575 149999 ... 0
142576 150000 ... 0
[142577 rows x 12 columns]
Index(['Unnamed: 0', 'SeriousDlqin2yrs',
'RevolvingUtilizationOfUnsecuredLines', 'age',
'NumberOfTime30-59DaysPastDueNotWorse', 'DebtRatio', 'MonthlyIncome',
'NumberOfOpenCreditLinesAndLoans', 'NumberOfTimes90DaysLate',
'NumberRealEstateLoansOrLines', 'NumberOfTime60-89DaysPastDueNotWorse',
'NumberOfDependents'],
dtype='object')